AgentFlow, an Evaluator, and a launch command
ready to go. The completed code lives at cookbooks/solver_judge_flow/.
Prerequisites
- rLLM installed (see this guide)
- Basic familiarity with Python
asyncioprogramming - A
TinkerAPI key withexport TINKER_API_KEY=<your_api_key>set in your environment (this tutorial uses the Tinker backend)
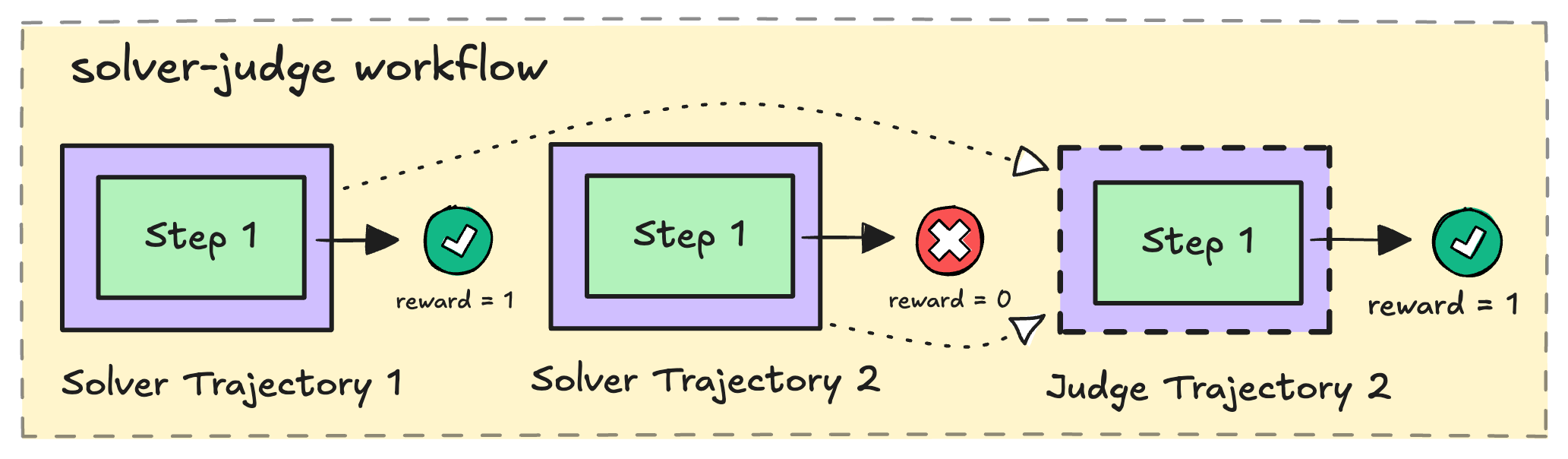
How the solver-judge workflow works
Here’s the high-level flow for a single task:- Solve —
Nsolver agents each receive the problem and generate a candidate solution in parallel. Below we takeN=2for simplicity. - Judge — A judge agent reviews all candidate solutions and selects the best one.
- Score — Each solver receives a reward based on whether its solution is correct. The judge receives a reward based on whether it selected a correct answer.
- Return — The flow packages everything into an
Episodethat the trainer uses to update the policy.
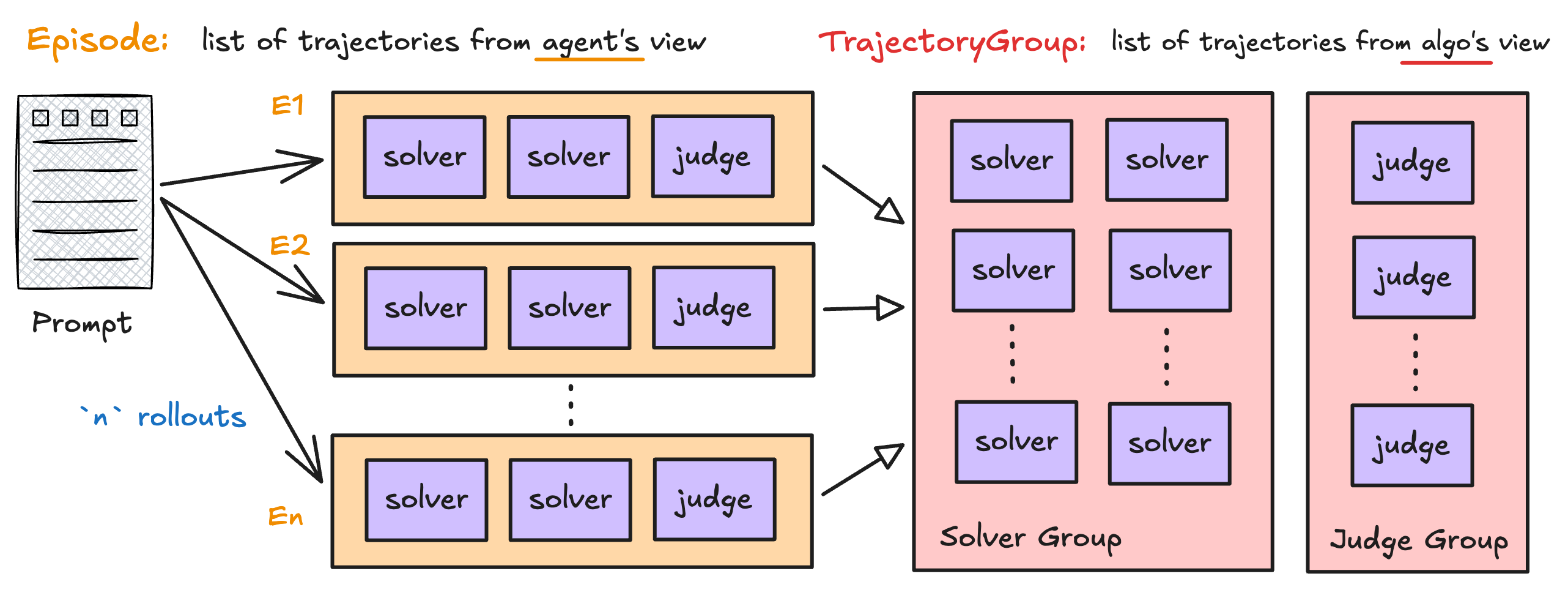
K rollouts per task, producing K × N solver trajectories and K judge trajectories — giving the RL algorithm plenty of signal to learn from.
A quick look at rLLM’s data model
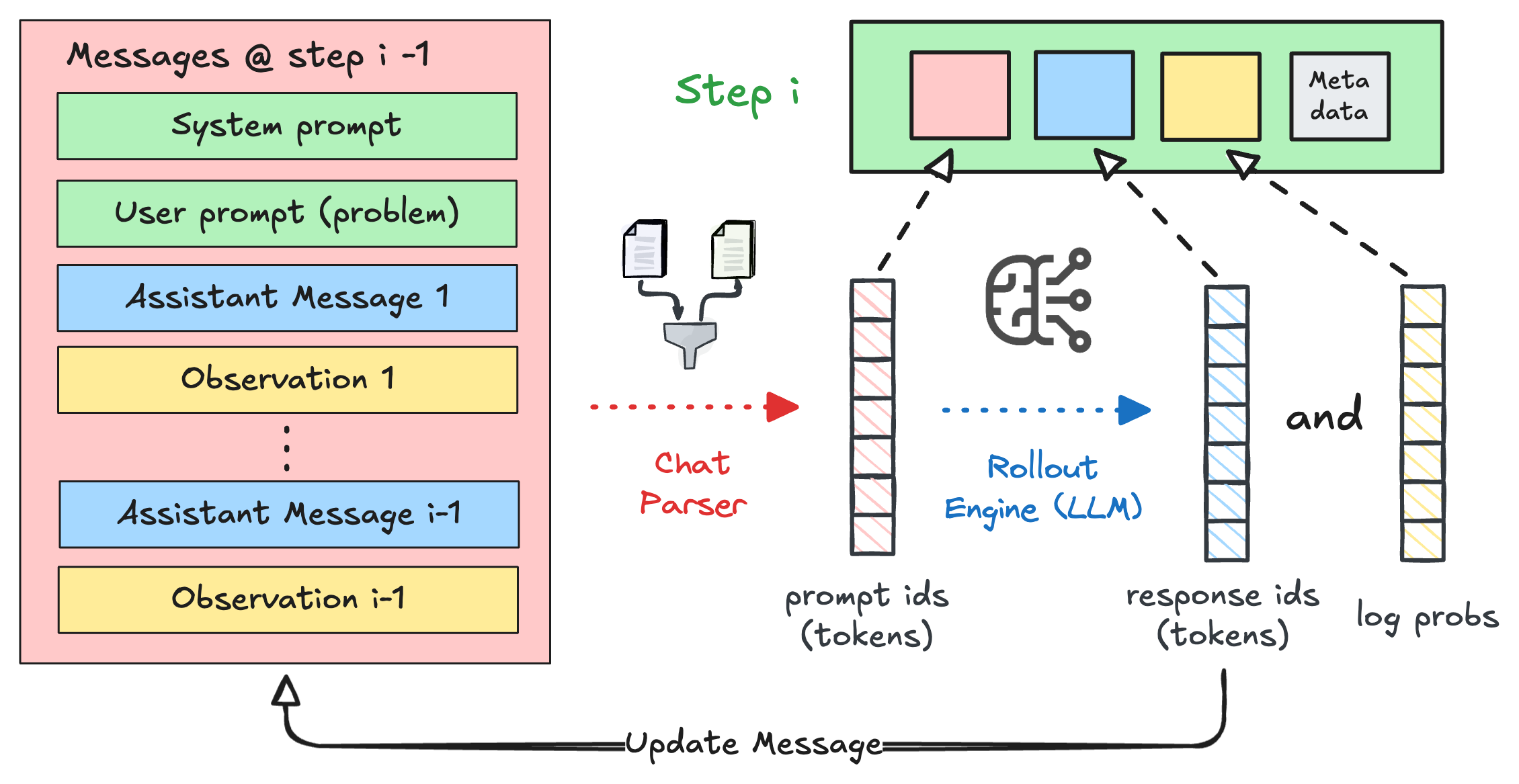
Before we start coding, let’s meet the three data structures you’ll be constructing in this tutorial. Think of them as nested containers — each one wraps the level below it.Step — one model interaction
AStep is the atomic unit: one call to the LLM. It captures the input messages,
the generated output, and (during training) the token IDs and log-probabilities. At
runtime, it also carries the parsed action.
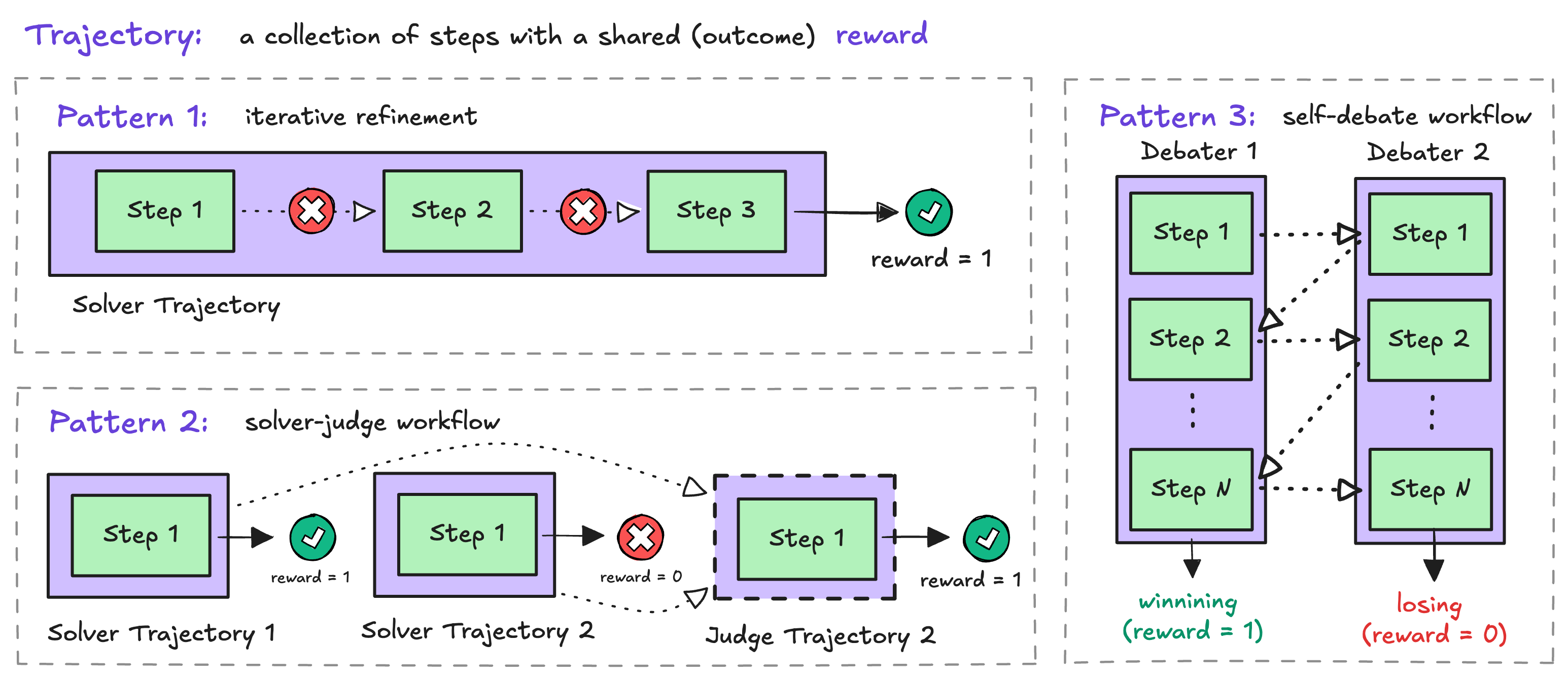
Trajectory — a role’s journey through the workflow
ATrajectory is an ordered list of Steps from a single role — for example, one
solver’s attempt or the judge’s evaluation. Each trajectory has a name (like
"solver" or "judge") that tells the trainer how to group trajectories together
for advantage computation.
Episode — the full picture from one rollout
AnEpisode is what your AgentFlow returns. It bundles all the trajectories from
a single rollout execution, along with metadata like is_correct and any artifacts
the evaluator will consume.
We’ll see each of these structures come to life as we build the flow below.
Building the AgentFlow
AnAgentFlow in rLLM is just a plain async function decorated with
@rllm.rollout(name=...). It takes a Task and an AgentConfig, talks to a model
via an OpenAI-compatible client, and returns an Episode.
The same code path runs both for evaluation and training. During training, the
config.base_url points at rLLM’s model gateway, which transparently captures
token IDs and log-probabilities for RL optimization. Your flow code doesn’t have
to change between the two modes.
1
Define the solver helper
The solver issues N parallel LLM calls — one per candidate solution — and wraps
each result in a A few things to notice:
Trajectory named "solver".- The trajectory is named
"solver"— this name is how rLLM groups trajectories during training. - Each
Stepcaptures the chat history (chat_completions), the raw model output (model_response), and the parsed answer (action). The token-level training data is filled in by the gateway during training. _generate_solutionslaunches N solvers concurrently withasyncio.gather, so they run in parallel.
2
Define the judge helper
The judge receives the problem and all candidate solutions, then returns one
trajectory named Same shape as the solver — one LLM call, one
"judge" whose action is the selected solution’s content
(resolved from the index the model outputs).Step, one Trajectory — but
named "judge". The judge’s action is the selected solution’s content
rather than an index, which makes it scoreable with the same reward function
used for solvers.3
Compose the AgentFlow
Now wrap the two helpers in a single async function decorated with
Walking through the function:
@rllm.rollout. This decorator marks the function as the entry point for
rLLM’s rollout engine.- Construct the OpenAI client pointed at
config.base_url. Same code for eval and training — only the URL changes. - Solvers run in parallel via the helper above. Result: a list of
"solver"trajectories. - Judge picks one using the parsed solutions. Result: a single
"judge"trajectory whoseactionis the chosen solution’s content. - Return an
Episodecontaining all trajectories and anartifacts["answer"]field that the evaluator will read.
Notice what’s not in the flow: any reward computation. Scoring lives in the
Evaluator (next step) — keeping the two concerns separate means the same flow
can be reused with different reward functions without code changes.
Building the Evaluator
The Evaluator is a second function — it reads theEpisode produced by the flow,
sets per-trajectory rewards, and returns an EvalOutput. rLLM’s trainer uses the
per-trajectory rewards to compute advantages separately for the solver and judge
trajectory groups.
- The evaluator iterates over every trajectory in the episode and writes
traj.rewarddirectly. The trainer reads these per-trajectory rewards when grouping by name and computing advantages. compute_scoreis a small reward helper fromrllm.rewards.countdown_rewardthat checks whether an arithmetic expression in<answer>...</answer>evaluates to the target number using only the allowed operations.- The top-level
EvalOutput.rewardis the episode-level reward (we use the judge’s score). Per-role accuracy is logged viaSignalentries.
Wiring it up as a cookbook
A cookbook is a small Python package that ships anAgentFlow plus an
Evaluator together with training scripts. Installing it makes both discoverable
via rllm’s entry-point system.
The directory layout (see cookbooks/solver_judge_flow/):
pyproject.toml registers the flow and evaluator under two well-known entry-point groups:
uv pip install -e cookbooks/solver_judge_flow, the rLLM CLI resolves
--agent solver_judge and --evaluator solver_judge_countdown directly.
See the Cookbooks tutorial for the full convention.
Training
With the flow and evaluator in place, training is a thin wrapper aroundAgentTrainer.
Writing the training script
DatasetRegistry.load_dataset— Loads the countdown dataset (combine the given numbers with arithmetic to reach a target). Pull it once withrllm dataset pull countdown.agent_flow=/evaluator=— The two functions you just wrote. The trainer drives the flow per-task, runs the evaluator on each episode, and uses the per-trajectory rewards for advantage estimation.backend="tinker"— Selects the Tinker backend for single-machine LoRA training. Other options include"verl"for distributed multi-GPU training.
Writing the launch script
The training script uses Hydra for configuration. A shell script keeps the override list manageable:
Run training with:
train_verl.sh instead.
What happens during training
With your flow and training script in place, here’s what the training loop does under the hood — tying back to the data model from earlier. For each batch of tasks:-
Generate episodes — The trainer runs
solver_judge_flowKtimes per task. Each run produces oneEpisodecontainingNsolver trajectories + 1 judge trajectory. -
Evaluate — The evaluator runs on each episode, writing per-trajectory rewards onto
traj.reward. -
Group trajectories — Episodes are regrouped into
TrajectoryGroups by name. All solver trajectories for the same task end up in one group; all judge trajectories in another.
-
Compute advantages — Within each group, an advantage estimator compares trajectories. By default GRPO uses the within-group reward distribution. With
K × Nsolver trajectories per task, the solver group has plenty of comparison signal; the judge group hasKtrajectories per task. - Update the policy — The shared model is updated to increase the probability of high-advantage trajectories and decrease low-advantage ones.
-
Validate — Periodically the trainer runs validation rollouts (without training) and reports
solver_accandjudge_accfrom the evaluator’ssignals.
Next steps
Cookbooks overview
The full cookbook authoring guide and a tour of the other examples
Unified trainer
Deep dive into the training loop architecture and 8-stage batch pipeline
Advantage estimator
Customize how advantages are computed per role
AgentFlow & Evaluator
The protocol the rLLM CLI and trainer dispatch through